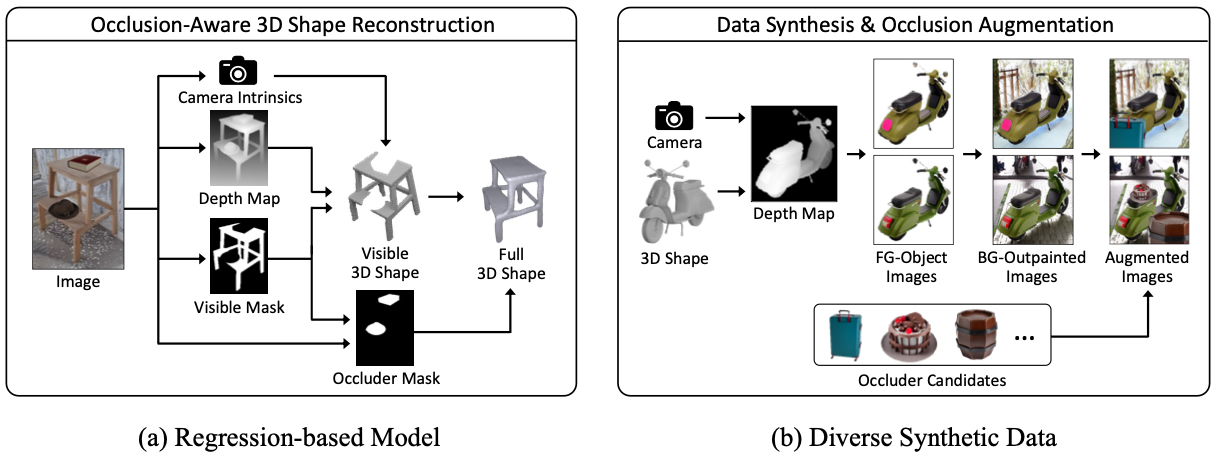
(a) Regression-based Model: Our model reconstructs the full 3D shape of a salient object using its visible 3D shape and the identified region of its occluders. The visible 3D shape is estimated from camera intrinsics, depth map, and visible region of the object.
(b) Diverse Synthetic Data: We create our training dataset by synthesizing diverse data. We render 3D shapes and then simulate their appearances and backgrounds using generative models. Occluders are inserted on-the-fly during model training.
Recent monocular 3D shape reconstruction methods have shown promising zero-shot results on object-segmented images without any occlusions. However, their effectiveness is significantly compromised in real-world conditions, due to imperfect object segmentation by off-the-shelf models and the prevalence of occlusions.
To effectively address these issues, we propose a unified regression model that integrates segmentation and reconstruction, specifically designed for occlusion-aware 3D shape reconstruction. To facilitate its reconstruction in the wild, we also introduce a scalable data synthesis pipeline that simulates a wide range of variations in objects, occluders, and backgrounds.
Training on our synthetic data enables the proposed model to achieve state-of-the-art zero-shot results on real-world images, using significantly fewer parameters than competing approaches.
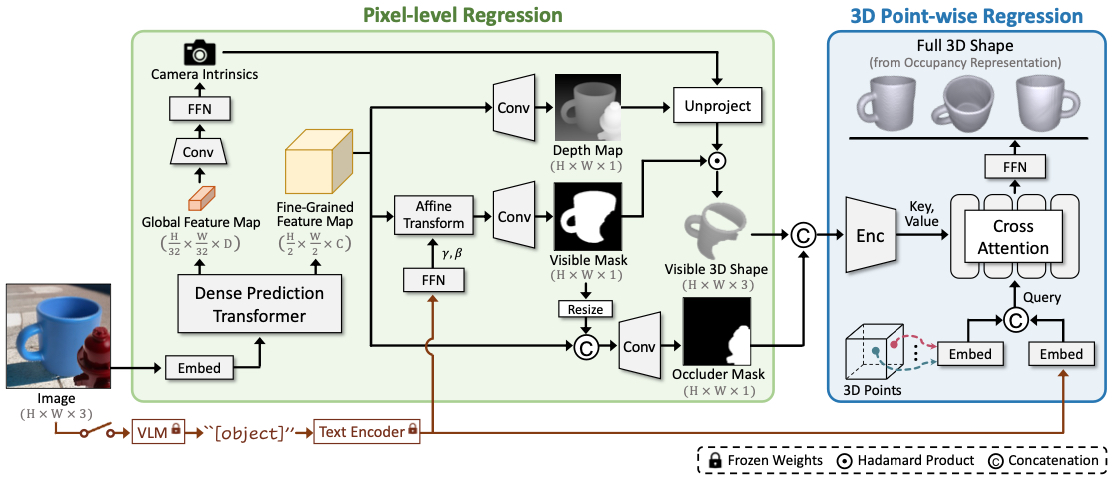
Overall architecture of ZeroShape-W. Given an object-centric RGB image, our model leverages the backbone of Dense Prediction Transformer (DPT) to regress camera intrinsics, a depth map, a visible mask of a salient object, and an occluder mask that represents the object's occluders. These components are used to derive the object's visible 3D shape, which is then combined with the occluder mask to regress occupancy values of 3D point queries through cross-attention layers. This process recovers the object's full 3D shape, including occluded parts. To alleviate difficulties of in-the-wild reconstruction, we optionally incorporate open-set category priors by estimating the object's category, "[object]" (e.g., "cup"), using an additional vision-language model (VLM).
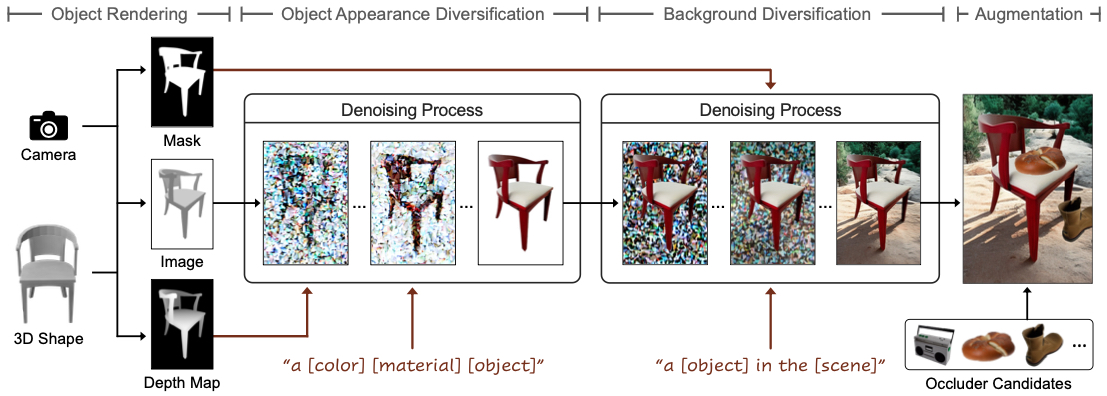
Overview of our data synthesis. Given a camera and 3D object, we render it to obtain an object mask, image, and depth map. We simulate object appearances via a conditional diffusion model using the depth as its spatial condition and "a [color] [material] [object]" (e.g., "a red wood chair") as its textual condition. To alleviate shape distortion by the generative model, we use the rendered image as initial guidance. We simulate its background via an object-aware background outpainting model using the mask and "a [object] in the [scene]" (e.g., "a chair in the canyon") as its textual condition. Then, we put occluders during data augmentation.
Diverse synthetic data produced by our scalable data synthesis pipeline. Based on 3D shape renderings from ShapeNet and Objaverse, we synthesize diverse images using ControlNet and object-aware background outpainting model.
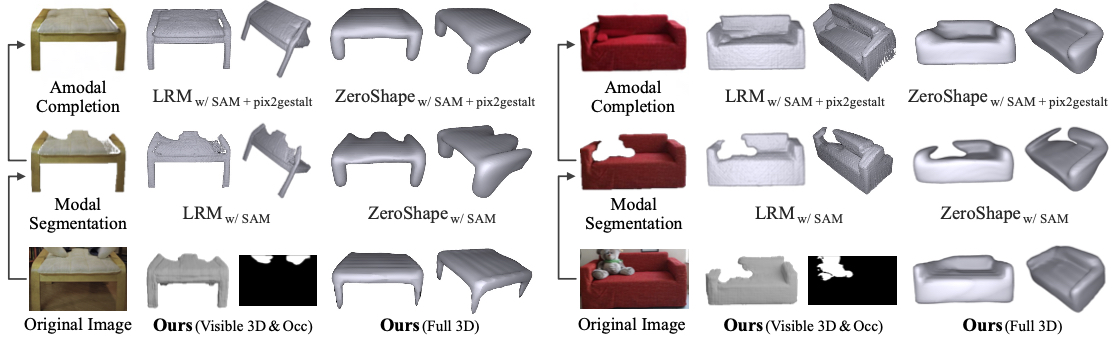
Qualitative comparison of single-view 3D shape reconstruction on Pix3D. We compare our model with state-of-the-art models, LRM and ZeroShape, which take modal segmentation results (from SAM) or amodal completion results (from pix2gestalt) as inputs. In contrast, our model directly takes original images as inputs, and performs occlusion-aware reconstruction by regressing visible 3D shapes and occluder silhouettes.
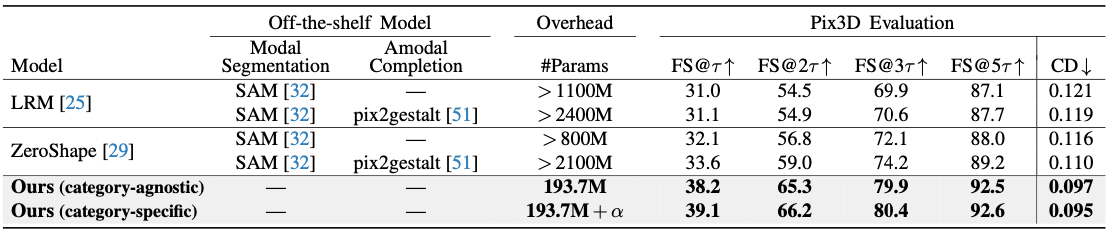
Quantitative comparison of single-view 3D shape reconstruction on Pix3D. Existing state-of-the-art reconstruction models, LRM and ZeroShape, require an off-the-shelf modal segmentation model (e.g., SAM), because they assume object-segmented images without any occlusions. For occlusion-aware reconstruction, they need an additional amodal completion model (e.g., pix2gestalt). In this comparison, our model is evaluated using the category-agnostic prompt "object".
ZeroShape-W (ZeroShape.W@gmail.com)
@InProceedings{cho2025robust,
title={Robust 3D Shape Reconstruction in Zero-Shot from a Single Image in the Wild},
author={Junhyeong Cho and Kim Youwang and Hunmin Yang and Tae-Hyun Oh},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}